Large-scale pretrained models are widely leveraged as foundations for learning new specialized tasks via fine-tuning, with the goal of maintaining the general performance of the model while allowing it to gain new skills. A valuable goal for all such models is robustness: the ability to perform well on out-of-distribution (OOD) tasks. We assess whether fine-tuning preserves the overall robustness of the pretrained model, and observed that models pretrained on large datasets exhibited strong catastrophic forgetting and loss of OOD generalization. To systematically assess robustness preservation in fine-tuned models, we propose the Robustness Inheritance Benchmark (ImageNet-RIB). The benchmark, which can be applied to any pretrained model, consists of a set of related but distinct OOD (downstream) tasks and involves fine-tuning on one of the OOD tasks in the set then testing on the rest. We find that though continual learning methods help, fine-tuning reduces robustness across pretrained models. Surprisingly, models pretrained on the largest and most diverse datasets (e.g., LAION-2B) exhibit both larger robustness losses and lower absolute robustness after fine-tuning on small datasets, relative to models pretrained on smaller datasets. These findings suggest that starting with the strongest foundation model is not necessarily the best approach for performance on specialist tasks.
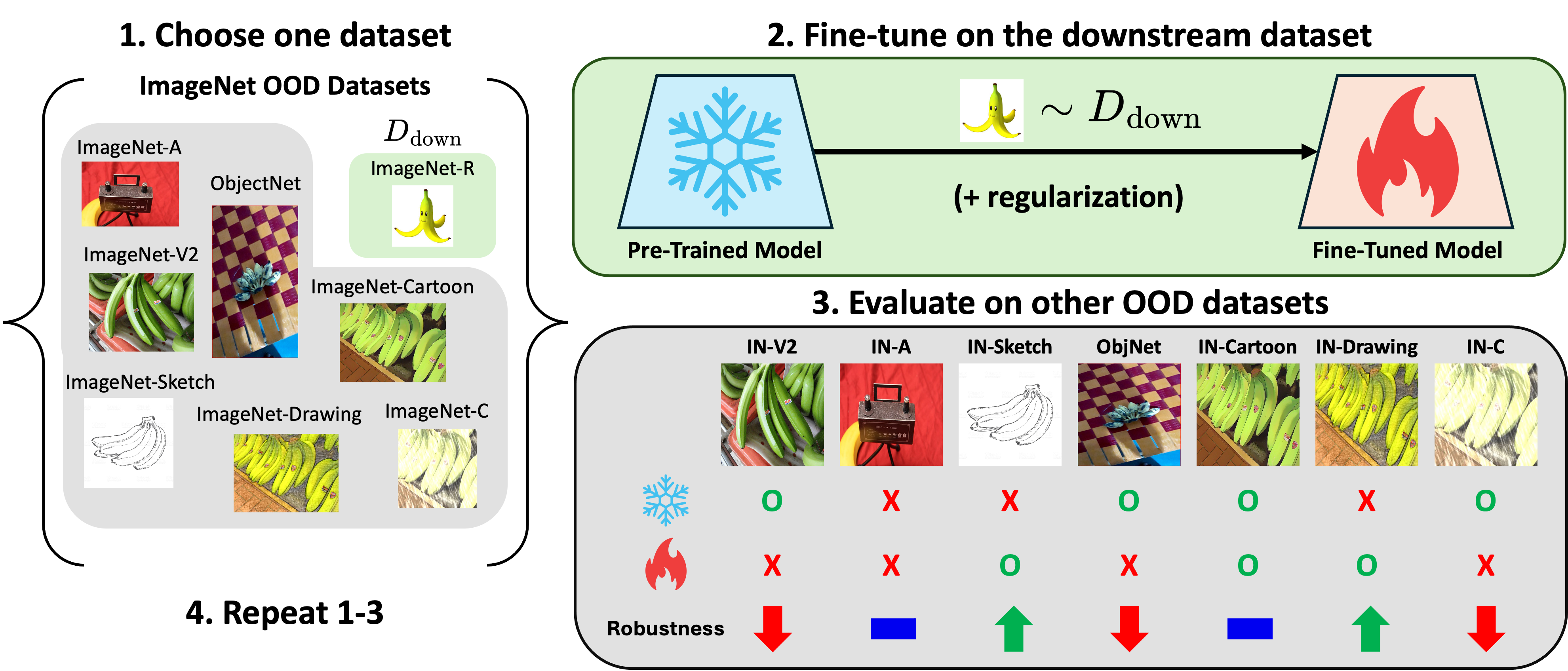
Illustration of the ImageNet-RIB (Robustness Improvement Benchmark). (1) We define a set $\mathbb{D}$ of ImageNet OOD datasets. We select one to use for fine-tuning, $D_\text{FT}$, then assess the performance of the pretrained model on $\mathbb{D} \setminus D_\text{FT}$. (2) After fine-tuning the pretrained model on $D_\text{FT}$, we (3) re-assess its performance on $\mathbb{D} \setminus D_\text{FT}$ and compute the robustness change. (4) This process is repeated until each dataset in ${\mathbb{D}}$ has been chosen once as the fine-tuning dataset, ensuring a detailed evaluation of fine-tuning's impact on robustness.
The robustness improvement (RI) on i-th downstream dataset is defined as the average accuracy difference between fine-tuned model and pre-trained models: $$RI_i = \frac{1}{N-1} \sum_{j=1, j \neq i}^N A^{(j)}_i - A_\text{pre}^{(j)}$$ $$mRI = \sum_i^N RI_i$$
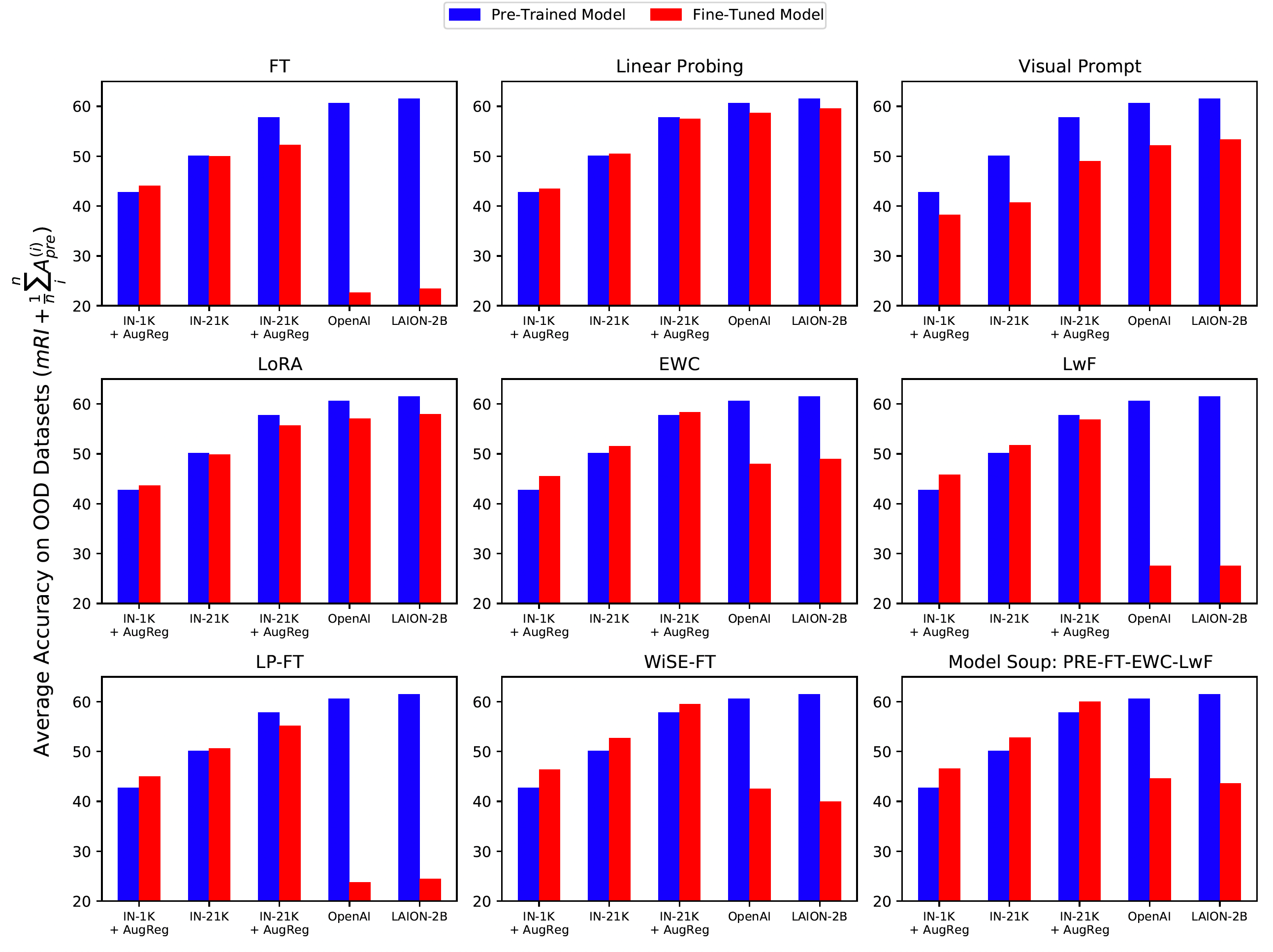
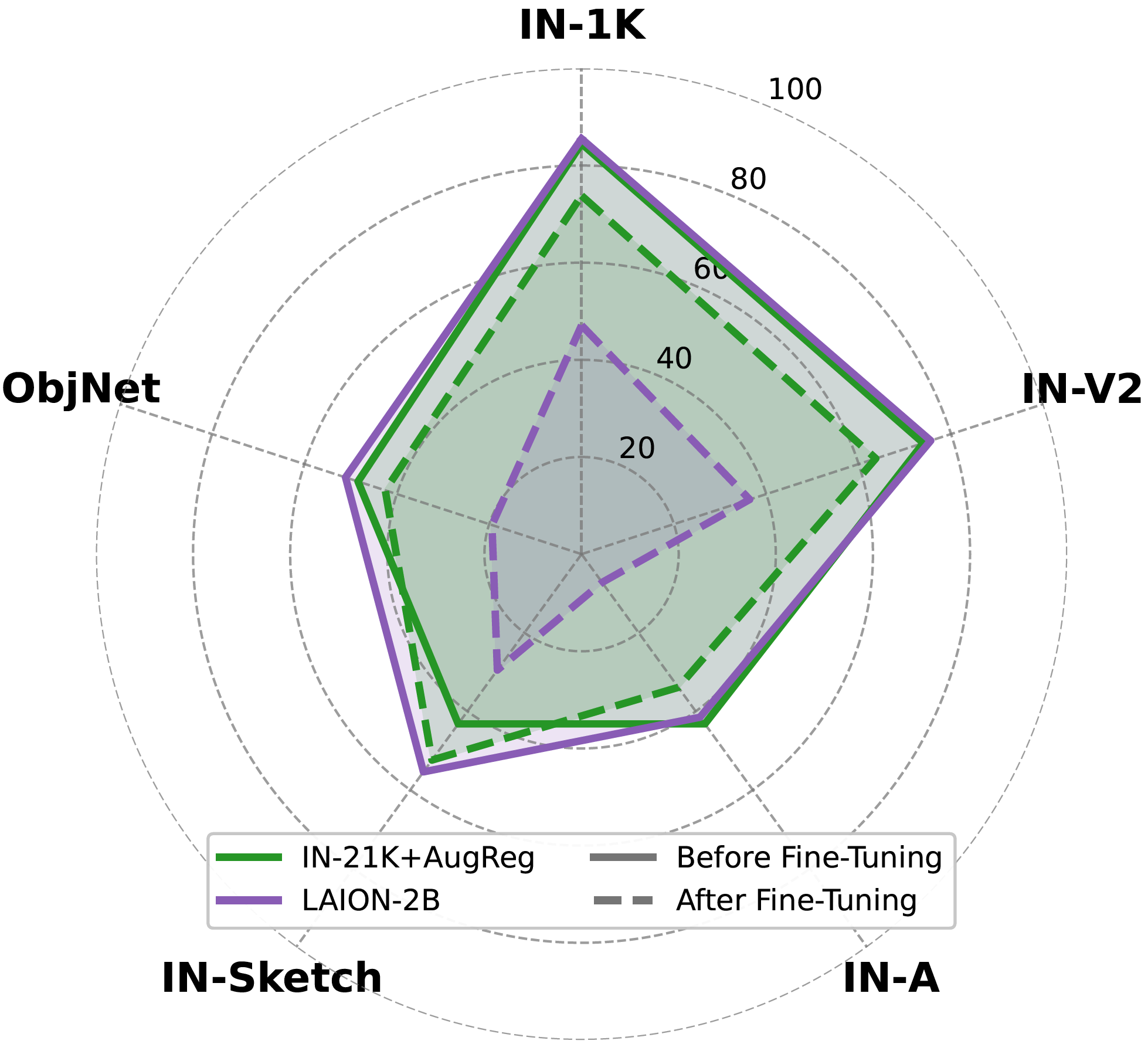
There are huge performance drops after fine-tuning on downstream datasets using OpenAI or LAION-2B pre-trained models.
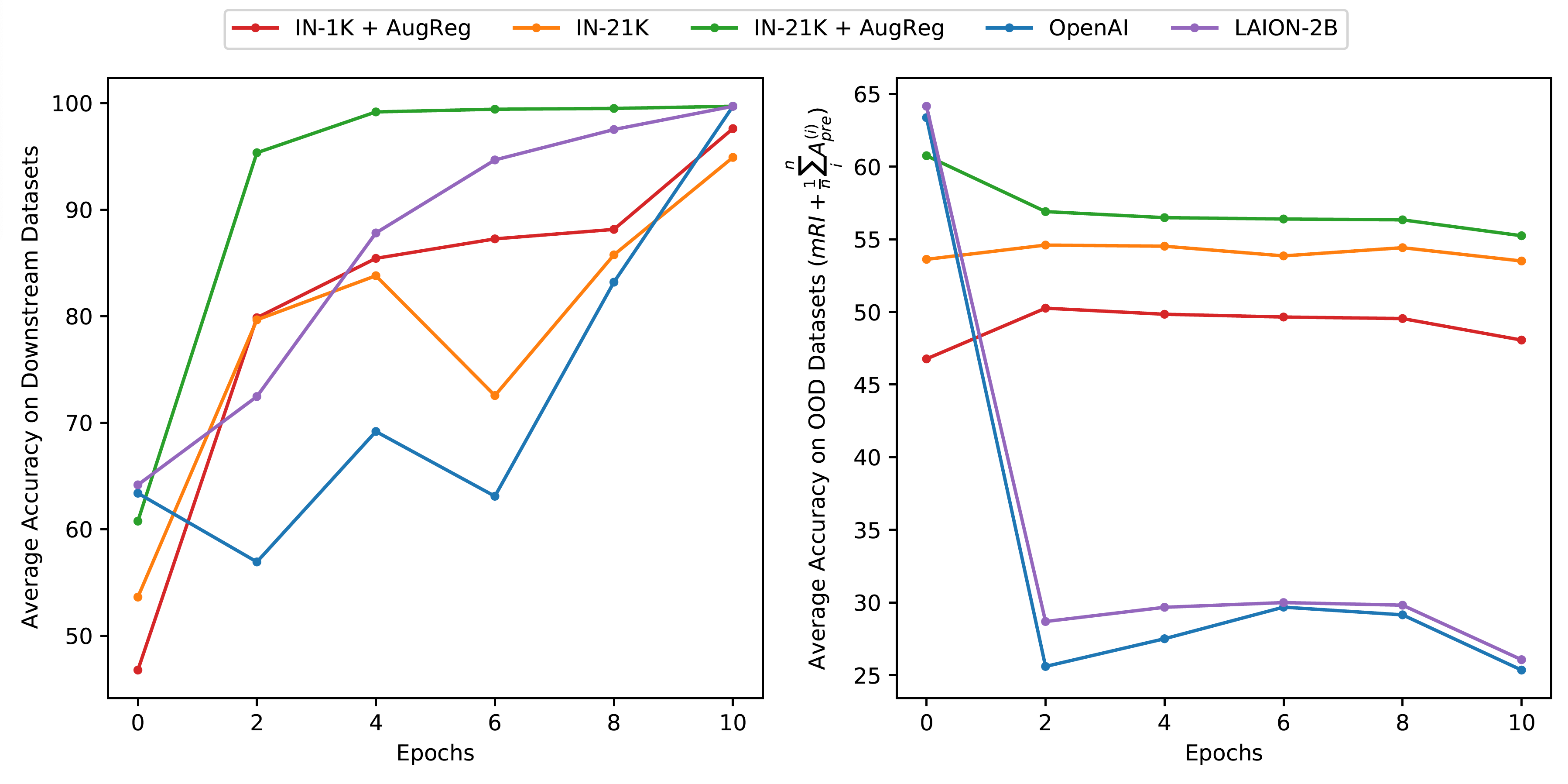
IN-21K with AugReg pre-trained models overfits on the downstream dataset and OpenAI pre-trained models learns the slowest. However, only OpenAI and LAION-2B pre-trained models suffer huge robustness degradation.
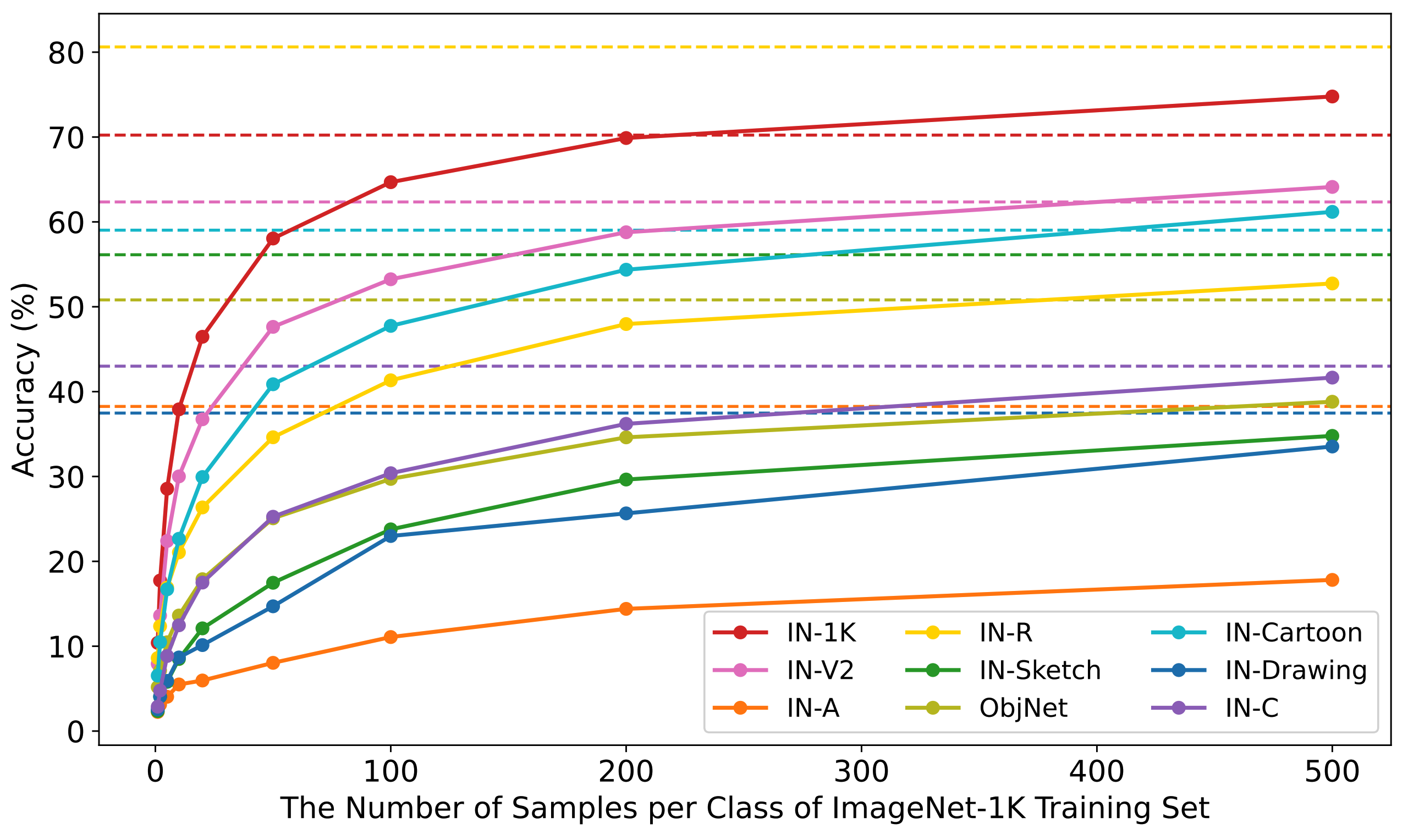
Rather, fine-tuning on small dataset leads severe catastrophic forgetting regardless of hyperparameter tuning.

This forgetting only happens when pretrianing dataset is larger than 100M and the fine-tuning dataset is small
@inproceedings{hwang2024imagenet,
title={ImageNet-RIB Benchmark: Large Pre-Training Datasets Don't Guarantee Robustness after Fine-Tuning},
author={Hwang, Jaedong and Cheung, Brian and Hong, Zhang-Wei and Boopathy, Akhilan and Agrawal, Pulkit and Fiete, Ila R},
booktitle={NeurIPSW on Fine-Tuning in Modern Machine Learning: Principles and Scalability},
year={2024}
}